Teaching Mid-air Hand Poses
Problem
Imagine a television interface that is controlled via 20 mid- air hand poses recognized by a depth camera. How do you communicate to users all gestures they can use in an interface? One possibility is the use of cheat sheets or instruction videos. Both require either space or time for watching and learning. How can we instantly reveal how a complex hand pose needs to be performed. Moreover, a hand pose always mapps to a command in the interface. How can we facilitate learning these pose-command mappings?
Criticism
One difficulty when applying gestures in the wild is that they need to be learned. The wide-spread distribution of the famous pinch-to-zoom gesture most likely took advantage of its public presentation in 2007, followed by a watch and imitate propaganda. However, this kind of gesture marketing does not scale to numerous gestures. If gestures are to become a significant part of computer input, new concepts are required that facilitate (1) gesture revelation and (2) the learning of gesture-command mappings.
The Key Idea

In order to explain to users how to perform these poses, MIME abstracts all hand poses to space-efficient line figures which users need to mime to trigger a command. Since users also need to learn which pose triggers which command, the line feedforward is embedded in command icons or names: by recalling a command's icon or name, users can also recall the embedded line figure and then perform an appropriate hand pose. For example, there could be a clock icon in the TV's web browser that opens the browsing history. A C shape is embedded in the icon (see Figure above) which users can imitate with their hand to access this shortcut. After explaining this logic once, users should even be able to deduce the formation of previously unknown poses.
Subjects learn significant faster when MIME is embedded into icons rather than text |
|
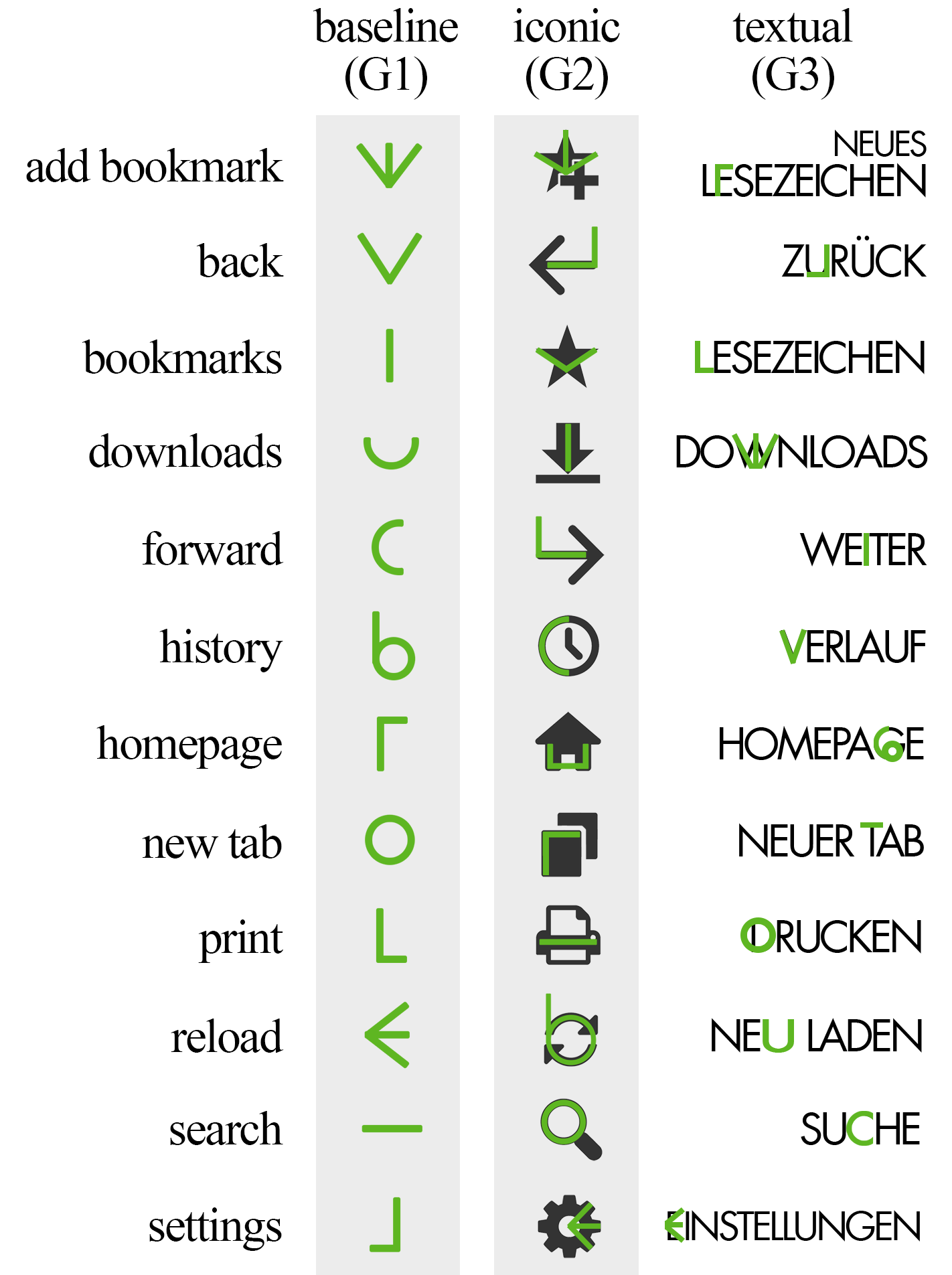 |
We performed a between subjects cognition study with 27 participants. Participants were randomly assigned to three groups: (G1) baseline, (G2) iconic, and (G3) textual (see Figure on the left). They trained the respective gesture vocabulary with mapping until they repeated it twice in a row without errors. They watched a 10-minute video for distraction. Then we tested the vocabulary again (short-term retention test). We invited participants back into the lab one week later and tested the vocabulary again (long-term retention test). Participants in the iconic group required significantly less repetition then participants in the textual or baseline group. They learned faster. Regarding retention, participants in the iconic group also retained significantly more items in the vocabulary when asked one week later compared to the baseline. |
Conclusion
Graphical user interface concepts, such as menus and other interactive elements, are established and have been optimized for the use of keyboards and single-pointing devices (e.g. mouse or touch screens). Previous research on gestural interaction did not take advantage of this established knowledge; gestures often remain invisible and hard to discover. We believe that this is due to the design choice of creating parallel worlds for gestural input and graphical user interface. With MIME we contribute a cross-reference between on-screen commands and off-screen mid-air hand poses, thus merging the graphical user interface world with the invisible gesture world. We encourage gesture designers to embrace the concepts of the graphical user interface and to use it as a platform for the design of novel gesture vocabularies.
Research Prototype
 |
We implemented MIME for Android smartphones and made the source code available for download (see below). By using off-the- shelf technology and releasing our code, we intended to facilitate experiment replication and further development by the research community. Camera images are processed in real-time using computer vision algorithms provided by OpenCV. The procedure to detect hand shapes is based on background subtraction, color blob detection in the HSV color space, morphological opening for noise removal, and contour detection. The computational load is reduced by scaling down camera frames prior to processing. On our test device (Samsung Galaxy S II, Android 4.4.4), the recognition routine achieves up to 15 FPS. |
| Hand pose detection is based on (1) finding the hand shape as described above, and (2) extraction of various features, including number and depth of convexity defects, number and size of holes, and image moments. In case a reliable classification based on these features and the known set of hand poses is not possible, the hand shapes' skeleton lines are computed using the Zhang-Suen thinning algorithm and passed to the $N Multistroke Recognizer for recognition. | |
Download Prototype
Reference
- Simon Ismair, Julie Wagner, Ted Selker, Andreas Butz "MIME: Teaching Mid-Air Pose-Command Mappings". MobileHCI'15: 17th international conference on Human-Computer Interaction with Mobile Devices and Services [paper]
- Video video
